The rapid advancement of deepfake technologies has sparked widespread public concern, particularly as face forgery poses a serious threat to public information security. However, the unknown and diverse forgery techniques, varied facial features and complex environmental factors pose significant challenges for face forgery analysis. Existing datasets lack descriptions of these aspects, making it difficult for models to distinguish between real and forged faces using only visual information amid various confounding factors. In addition, existing methods do not yield user-friendly and explainable results, complicating the understanding of the model's decision-making process. To address these challenges, we made the following contributions:
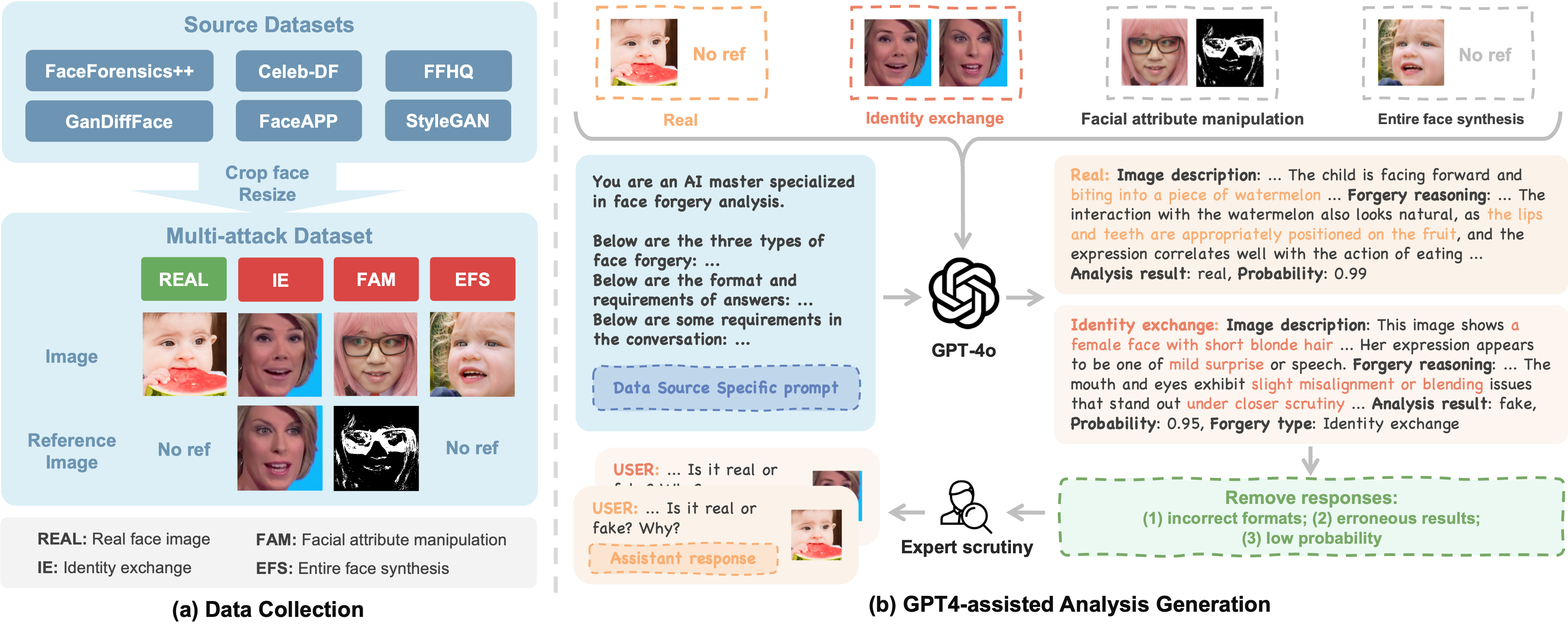
We utilize FF++, Celeb-DF-v2, DFFD (FFHQ, FaceApp, StyleGAN) and GanDiffFace as our source datasets since they encompass diverse forgery techniques and enriched facial characteristics. Subsequently, we construct the Multi-attack (MA) dataset, comprising 95K images with diverse facial features and various types of forgeries. Then, we employ GPT-4o to generate face forgery analysis processes. Finally, experts scrutinize the analysis process and the qualified responses are organized into a VQA format, resulting in 20K high-quality face forgery analysis VQA data.
| Data file name | File Size | Sample Size |
|---|---|---|
| ffa_vqa_20k.json | 32.4 MB | 20K |
| mistral_ffa_vqa_90k.json | 98.2 MB | 30K |

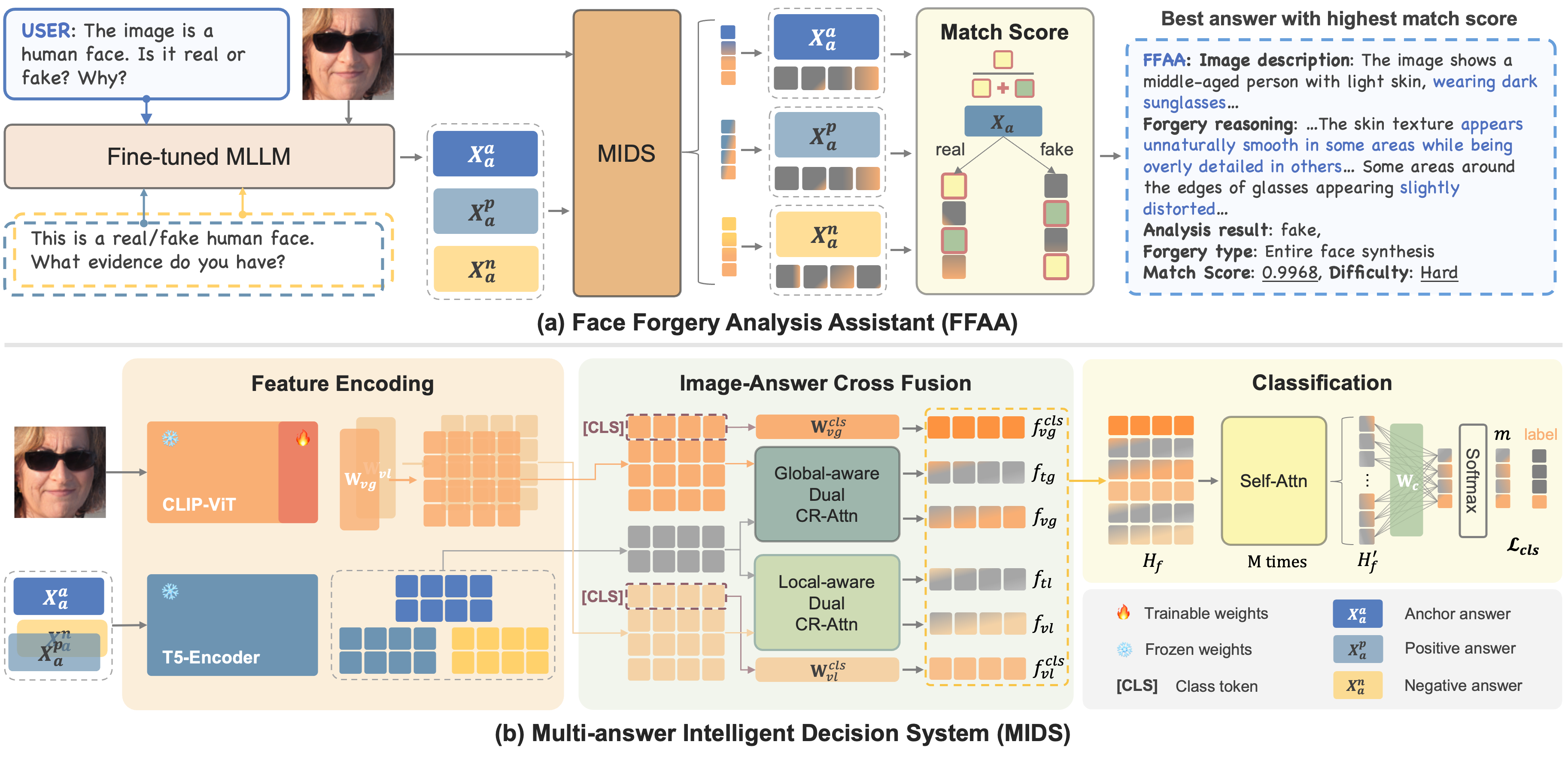
FFAA primarily consists of two modules: a fine-tuned Multimodal Large Language Model (MLLM) and Multi-answer Intelligent Decision System (MIDS). MIDS is proposed to select the answer that best matches the image's authenticity, mitigating the impact of fuzzy classification boundaries between real and forged faces, thereby enhancing model's robustness. We consider a two-stage training procedure:
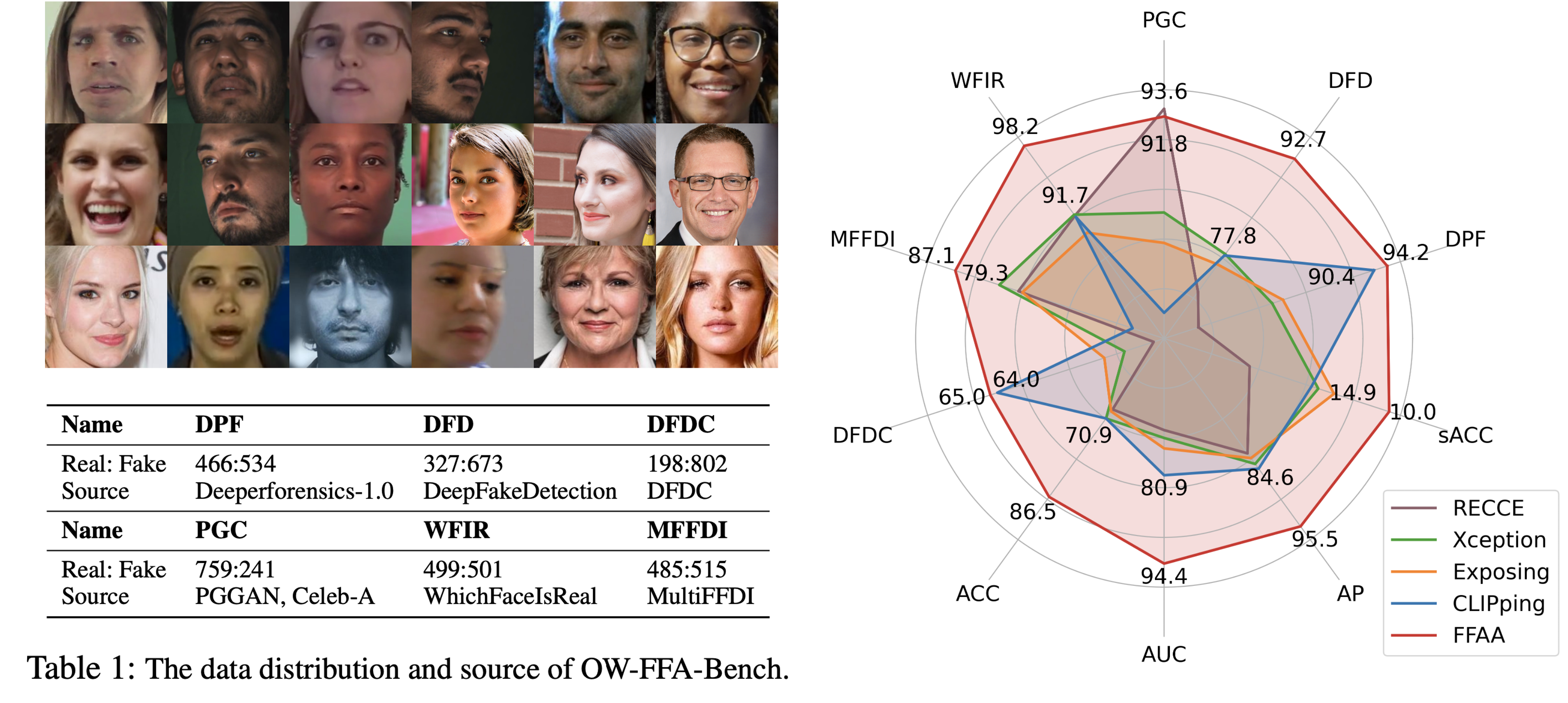
We create the generalization test sets of the OW-FFA-Bench by randomly collecting face images from the public datasets: Deeperforensics (DPF), DeepFakeDetection (DFD), DFDC, PGGAN, Celeb-A, WhichFaceIsReal (WFIR) and MultiFFDI (MFFDI). The images are then divided into six generalization test sets based on their source, with each containing 1K images and differing in distribution. FFAA achieves state-of-the-art generalization performance on the OW-FFA-Bench with an ACC of 86.5% and an AUC of 94.4%, and demonstrates excellent robustness with an sACC of 10.0%

We compare FFAA with advanced MLLMs in face forgery analysis, including LLaVA-v1.6-34b and GPT-4o. Judgment results are indicated in parentheses as ('Real', 'Fake', 'Refuse to judge'), with green for correct judgments and red for incorrect ones. These advanced MLLMs exhibit strong image understanding capabilities but often struggle to determine face authenticity, sometimes avoiding definitive conclusions. In contrast, FFAA not only understands the image but also conducts a reasoned analysis of authenticity from various perspectives.
We present eight face images from different sources, along with the heatmap visualizations of MIDS's Fvl and Fvg, and several key information from FFAA's answers. It can be observed that Fvl tends to focus on specific facial features, the surrounding environment, and more apparent local forgery marks or authenticity clues, whereas Fvg emphasizes more abstract features (e.g., 'smoothness', 'lighting', 'shadows', 'integration'). In some cases, such as examples (a), (b) and (c), Fvl and Fvg may rely on the same features as clues for assessing the authenticity of the face.
@article{huang2024ffaa,
title={FFAA: Multimodal Large Language Model based Explainable Open-World Face Forgery Analysis Assistant},
author={Huang, Zhengchao and Xia, Bin and Lin, Zicheng and Mou, Zhun and Yang, Wenming},
journal={arXiv preprint arXiv:2408.10072},
year={2024}
}This website is modified from LLaVA and LLMGA, both of which are outstanding works! We thank the LLaVA team for giving us access to their models, and open-source projects.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
